Una breve historia del
reconocimiento de voz
Ha habido más progreso en la tecnología de reconocimiento de voz en los últimos 30 meses que en los primeros 30 años.
La potencia de cálculo y la inteligencia artificial están detrás de los avances en este campo. Con cantidades masivas de datos de voz combinadas con un procesamiento más rápido, el reconocimiento de voz ha llegado a un punto de inflexión donde sus capacidades están casi a la par con las humanas.
El siguiente gráfico pertenece al informe de tendencias de Internet de 2017 de Mary Meeker (nota: ya no está disponible en Slideshare). Muestra la tasa de precisión de palabras de Google, que recientemente superó el umbral del 95% de precisión humana.
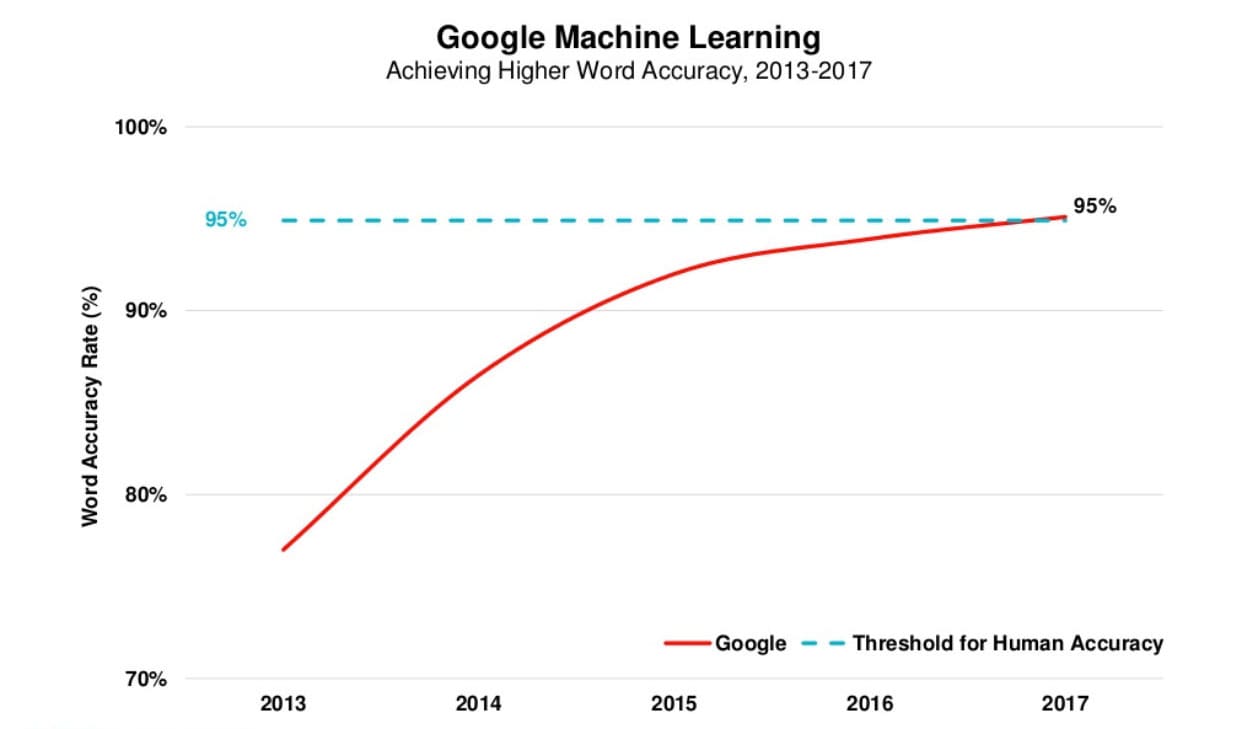
Aunque ha habido grandes avances recientemente, el reconocimiento de voz se remonta a principios de la década de 1950. A continuación se presentan algunos de los eventos clave que han dado forma a esta tecnología en los últimos 70 años.
Años 50 y 60
Los primeros sistemas de reconocimiento de voz se centraban en los números, no en las palabras. En 1952, Bell Laboratories diseñó el sistema "Audrey", que podía reconocer una sola voz pronunciando dígitos en voz alta. Diez años después, IBM presentó "Shoebox", que entendía y respondía a 16 palabras en inglés.
En todo el mundo, otras naciones desarrollaron hardware que podía reconocer el sonido y el habla. A finales de los años 60, la tecnología ya podía soportar palabras con cuatro vocales y nueve consonantes.
Años 70
El reconocimiento de voz logró varios avances significativos en esta década. Esto se debió principalmente al Departamento de Defensa de los EE. UU. y a DARPA. El programa Speech Understanding Research (SUR) que dirigieron fue uno de los más grandes de su tipo en la historia del reconocimiento de voz. El sistema de voz "Harpy" de Carnegie Mellon surgió de este programa y era capaz de entender más de 1,000 palabras, lo que equivale aproximadamente al vocabulario de un niño de tres años.
También fue significativo en los años 70 la introducción por parte de Bell Laboratories de un sistema que podía interpretar múltiples voces.
Años 80
En los años 80, el vocabulario del reconocimiento de voz pasó de unos pocos cientos de palabras a varios miles. Uno de los avances provino de un método estadístico conocido como el "Modelo Oculto de Markov (HMM)". En lugar de limitarse a usar palabras y buscar patrones de sonido, el HMM estimaba la probabilidad de que los sonidos desconocidos fueran realmente palabras.
Años 90
El reconocimiento de voz avanzó notablemente en los años 90 en gran parte gracias a la computadora personal. Procesadores más rápidos permitieron que software como Dragon Dictate se utilizara de forma más generalizada.
BellSouth introdujo el portal de voz (VAL), un sistema interactivo de reconocimiento de voz por marcación telefónica. Este sistema dio origen a la infinidad de sistemas de menús telefónicos que todavía existen hoy en día.
Años 2000
Para el año 2001, la tecnología de reconocimiento de voz había alcanzado una precisión cercana al 80%. Durante la mayor parte de la década no hubo muchos avances hasta que llegó Google con el lanzamiento de Google Voice Search. Al ser una aplicación, puso el reconocimiento de voz en manos de millones de personas. También fue importante porque la potencia de procesamiento podía derivarse a sus centros de datos. No solo eso, Google estaba recopilando datos de miles de millones de búsquedas que podían ayudarle a predecir lo que una persona estaba diciendo realmente. En aquel momento, el sistema de búsqueda por voz en inglés de Google incluía 230 mil millones de palabras procedentes de las búsquedas de los usuarios.
Años 2010
En 2011, Apple lanzó Siri, que era similar a la búsqueda por voz de Google. La primera parte de esta década vio una explosión de otras aplicaciones de reconocimiento de voz. Y con Alexa de Amazon y Google Home, hemos visto cómo los consumidores se sienten cada vez más cómodos hablando con las máquinas.
Hoy en día, algunas de las mayores empresas tecnológicas compiten por ostentar el título de mayor precisión de voz. En 2016, IBM alcanzó una tasa de error de palabras del 6,9 por ciento. En 2017, Microsoft superó a IBM con una cifra del 5,9 por ciento. Poco después, IBM mejoró su tasa al 5,5 por ciento. Sin embargo, es Google quien reclama la tasa más baja con un 4,9 por ciento.
El futuro del reconocimiento de voz
La tecnología necesaria para las aplicaciones de voz es ahora potente y relativamente económica. Con los avances en la inteligencia artificial y la creciente cantidad de datos de voz que pueden extraerse fácilmente, es muy posible que la voz se convierta en la próxima interfaz dominante.
En Sonix, agradecemos a las muchas empresas que nos precedieron y que impulsaron el reconocimiento de voz hasta donde se encuentra hoy. Automatizamos el flujo de trabajo de transcripción y lo hacemos rápido, fácil y asequible. No podríamos hacer eso sin el increíble trabajo previo.
Pruebe Sonix gratis
Sonix transcribe, pone marcas de tiempo y organiza sus archivos de audio y vídeo para que pueda buscar, editar y compartir su contenido multimedia.
Incluye 30 minutes minutos de transcripción gratuita