Eine kurze Geschichte der Spracherkennung
In den letzten 30 Monaten gab es mehr Fortschritte in der Spracherkennungstechnologie als in den ersten 30 Jahren.
Rechenleistung und künstliche Intelligenz sind maßgeblich für die Fortschritte in diesem Bereich verantwortlich. Mit massiven Mengen an Sprachdaten in Kombination mit schnellerer Verarbeitung hat die Spracherkennung einen Wendepunkt erreicht, an dem ihre Fähigkeiten in etwa auf Augenhöhe mit denen des Menschen liegen.
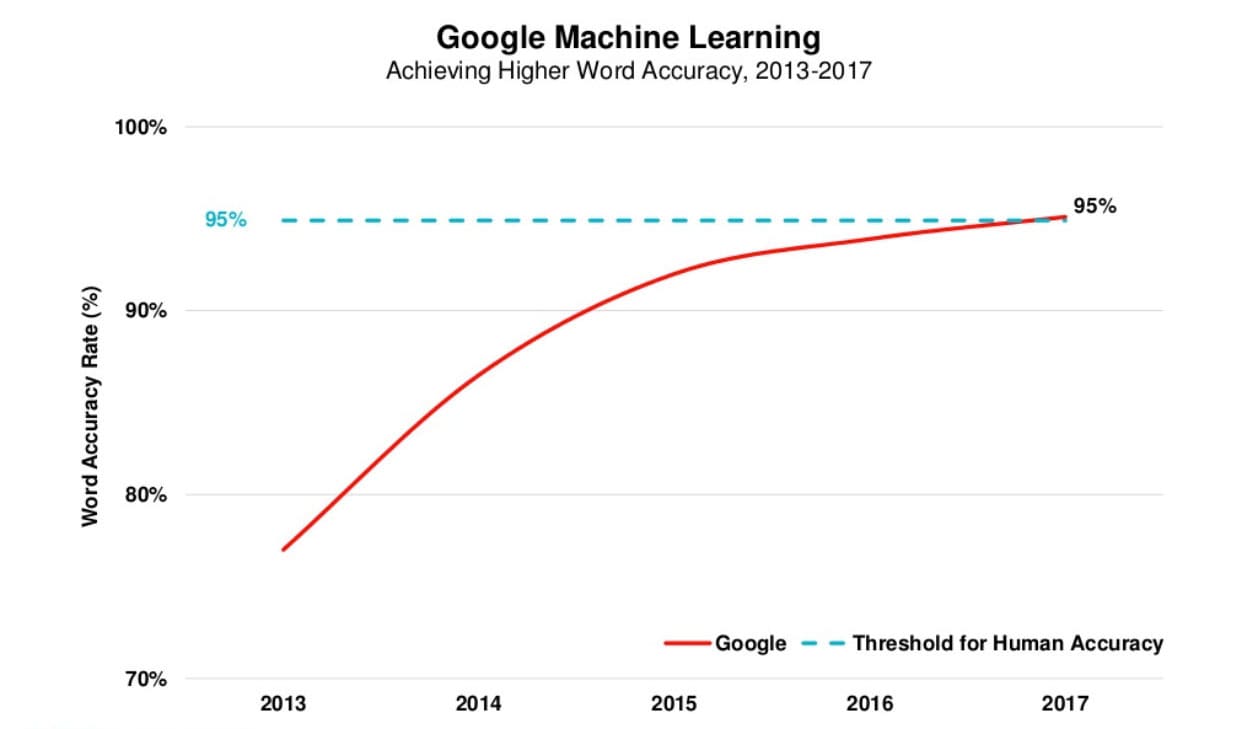
Die untenstehende Grafik stammt aus Mary Meekers Internet Trends Report 2017 (Hinweis: nicht mehr auf Slideshare verfügbar). Sie stellt die Wortgenauigkeitsrate von Google dar, die kürzlich die 95%-Schwelle für menschliche Genauigkeit überschritten hat.
Während es in letzter Zeit enorme Fortschritte gegeben hat, reicht die Spracherkennung bis in die frühen 1950er Jahre zurück. Nachfolgend sind einige der wichtigsten Ereignisse aufgeführt, die diese Technologie in den letzten 70 Jahren geprägt haben.
1950er und 60er Jahre
Die ersten Spracherkennungssysteme konzentrierten sich auf Zahlen, nicht auf Wörter. 1952 entwickelten die Bell Laboratories das "Audrey"-System, das eine einzelne Stimme erkennen konnte, die Ziffern laut aussprach. Zehn Jahre später stellte IBM "Shoebox" vor, das 16 Wörter in Englisch verstand und darauf reagierte.
Rund um den Globus entwickelten andere Nationen Hardware, die Geräusche und Sprache erkennen konnte. Und bis zum Ende der 60er Jahre konnte die Technologie Wörter mit vier Vokalen und neun Konsonanten unterstützen.
1970er Jahre
Die Spracherkennung machte in diesem Jahrzehnt mehrere bedeutende Fortschritte. Dies war vor allem dem US-Verteidigungsministerium und der DARPA zu verdanken. Das von ihnen durchgeführte Speech Understanding Research (SUR)-Programm war eines der größten seiner Art in der Geschichte der Spracherkennung. Das "Harpy"-Sprachsystem der Carnegie Mellon University ging aus diesem Programm hervor und war in der Lage, über 1.000 Wörter zu verstehen, was etwa dem Wortschatz eines Dreijährigen entspricht.
Bedeutend in den 70er Jahren war auch die Einführung eines Systems durch die Bell Laboratories, das mehrere Stimmen interpretieren konnte.
1980er Jahre
In den 80er Jahren stieg der Wortschatz der Spracherkennung von einigen hundert auf mehrere tausend Wörter. Einer der Durchbrüche kam durch eine statistische Methode namens "Hidden Markov Model (HMM)". Anstatt nur Wörter zu verwenden und nach Klangmustern zu suchen, schätzte das HMM die Wahrscheinlichkeit, dass die unbekannten Klänge tatsächlich Wörter sind.
1990er Jahre
Die Spracherkennung wurde in den 90er Jahren maßgeblich durch den Personal Computer vorangetrieben. Schnellere Prozessoren machten es möglich, dass Software wie Dragon Dictate eine breitere Anwendung fand.
BellSouth führte das Sprachportal (VAL) ein, ein interaktives Spracherkennungssystem für Einwahlverbindungen. Dieses System war die Geburtsstunde der unzähligen Telefonbaum-Systeme, die es heute noch gibt.
2000er Jahre
Bis zum Jahr 2001 hatte die Spracherkennungstechnologie eine Genauigkeit von nahezu 80% erreicht. Während des größten Teils des Jahrzehnts gab es kaum Fortschritte, bis Google mit der Einführung der Google Voice Search auf den Plan trat. Da es sich um eine App handelte, gelangte die Spracherkennung in die Hände von Millionen von Menschen. Es war auch deshalb bedeutend, weil die Rechenleistung in die Rechenzentren ausgelagert werden konnte. Darüber hinaus sammelte Google Daten von Milliarden von Suchanfragen, was dem System half vorherzusagen, was eine Person tatsächlich sagt. Zu dieser Zeit umfasste das englische Voice Search System von Google 230 Milliarden Wörter aus Nutzersuchen.
2010er Jahre
Im Jahr 2011 brachte Apple Siri auf den Markt, was der Google Voice Search ähnelte. Der frühe Teil dieses Jahrzehnts erlebte eine Explosion anderer Spracherkennungs-Apps. Mit Amazon Alexa und Google Home haben wir gesehen, dass sich Verbraucher immer mehr daran gewöhnen, mit Maschinen zu sprechen.
Heute konkurrieren einige der größten Technologieunternehmen um den Titel der höchsten Sprachgenauigkeit. Im Jahr 2016 erreichte IBM eine Wortfehlerrate von 6,9 Prozent. 2017 löste Microsoft IBM mit einem Wert von 5,9 Prozent ab. Kurz darauf verbesserte IBM seine Rate auf 5,5 Prozent. Google behauptet jedoch mit 4,9 Prozent die niedrigste Rate für sich.
Die Zukunft der Spracherkennung
Die Technologie zur Unterstützung von Sprachanwendungen ist heute sowohl relativ kostengünstig als auch leistungsstark. Mit den Fortschritten in der künstlichen Intelligenz und den zunehmenden Mengen an Sprachdaten, die leicht erschlossen werden können, ist es sehr wahrscheinlich, dass Sprache die nächste dominante Schnittstelle wird.
Wir bei Sonix danken den vielen Unternehmen vor uns, die die Spracherkennung dorthin gebracht haben, wo sie heute steht. Wir automatisieren den Transkriptions-Workflow und machen ihn schnell, einfach und erschwinglich. Ohne die erstaunliche Arbeit, die vor uns geleistet wurde, könnten wir das nicht tun.
Sonix kostenlos testen
Sonix transkribiert, versieht mit Zeitstempeln und organisiert Ihre Audio- und Videodateien, damit Sie Ihre Medien suchen, bearbeiten und teilen können.
Beinhaltet 30 minutes Minuten kostenlose Transkription