Een korte geschiedenis van
spraakherkenning
Er is in de afgelopen 30 maanden meer vooruitgang geboekt in de spraakherkenningstechnologie dan in de eerste 30 jaar.
Rekenkracht en kunstmatige intelligentie liggen grotendeels ten grondslag aan de vooruitgang op dit gebied. Met enorme hoeveelheden spraakdata in combinatie met snellere verwerking heeft spraakherkenning een omslagpunt bereikt waarbij de mogelijkheden ongeveer gelijk zijn aan die van mensen.
De onderstaande grafiek is afkomstig uit Mary Meekers Internet Trends rapport van 2017 (let op: niet langer beschikbaar op Slideshare). Het toont de woordnauwkeurigheid van Google, die onlangs de drempel van 95% voor menselijke nauwkeurigheid overschreed.
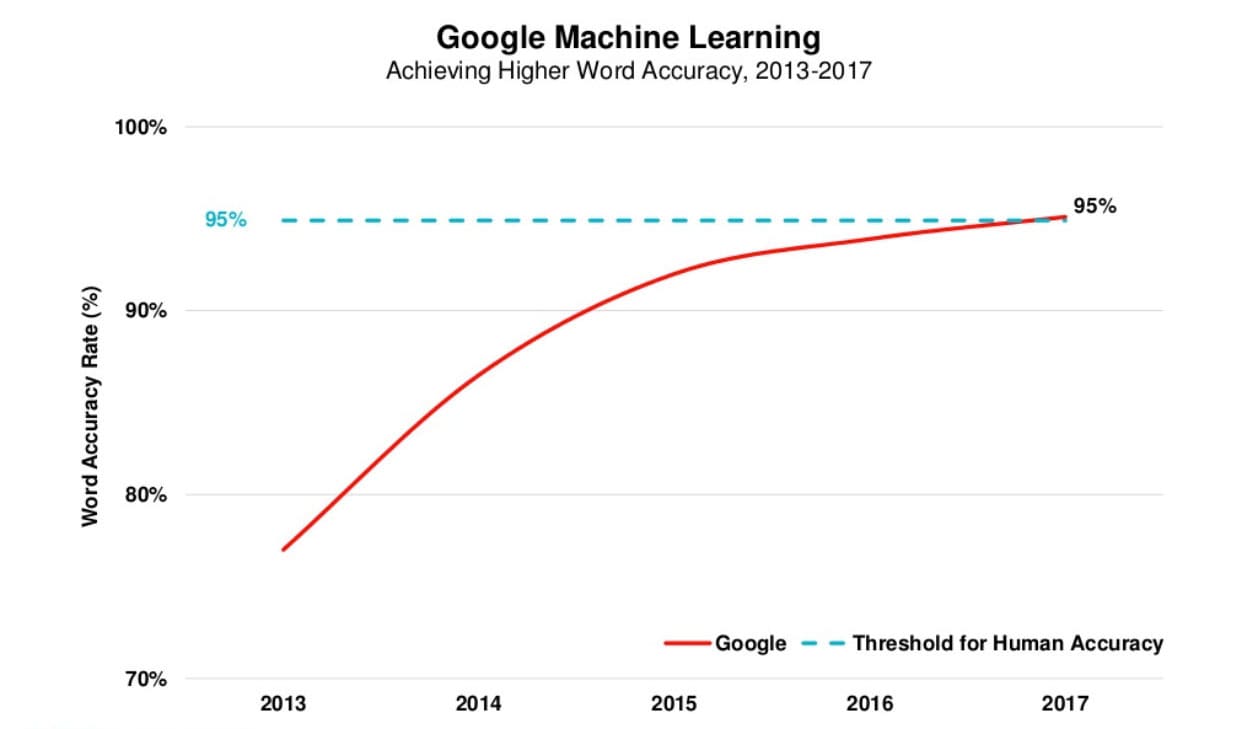
Hoewel er de laatste tijd enorme stappen zijn gezet, dateert spraakherkenning al uit de vroege jaren 50. Hieronder staan enkele van de belangrijkste gebeurtenissen die deze technologie de afgelopen 70 jaar hebben gevormd.
Jaren 50 en 60
De eerste spraakherkenningssystemen waren gericht op cijfers, niet op woorden. In 1952 ontwierp Bell Laboratories het "Audrey"-systeem dat een enkele stem kon herkennen die cijfers hardop uitsprak. Tien jaar later introduceerde IBM "Shoebox" die 16 woorden in het Engels begreep en beantwoordde.
Wereldwijd ontwikkelden ook andere landen hardware die geluid en spraak kon herkennen. Tegen het einde van de jaren 60 kon de technologie woorden met vier klinkers en negen medeklinkers ondersteunen.
Jaren 70
Spraakherkenning maakte in dit decennium verschillende betekenisvolle vorderingen. Dit was grotendeels te danken aan het Amerikaanse ministerie van Defensie en DARPA. Het Speech Understanding Research (SUR) programma dat zij uitvoerden, was een van de grootste in zijn soort in de geschiedenis van de spraakherkenning. Het "Harpy"-spraaksysteem van Carnegie Mellon kwam voort uit dit programma en was in staat om meer dan 1.000 woorden te begrijpen, wat ongeveer gelijk is aan de woordenschat van een driejarige.
Ook belangrijk in de jaren 70 was de introductie door Bell Laboratories van een systeem dat meerdere stemmen kon interpreteren.
Jaren 80
In de jaren 80 groeide de woordenschat van spraakherkenning van een paar honderd woorden naar enkele duizenden woorden. Een van de doorbraken kwam van een statistische methode die bekend staat als het "Hidden Markov Model (HMM)". In plaats van alleen woorden te gebruiken en naar geluidspatronen te zoeken, schatte het HMM de waarschijnlijkheid in dat onbekende geluiden daadwerkelijk woorden waren.
Jaren 90
Spraakherkenning werd in de jaren 90 vooruitgeholpen, grotendeels dankzij de personal computer. Snellere processors maakten het mogelijk voor software zoals Dragon Dictate om breder in gebruik te worden genomen.
BellSouth introduceerde het voice portal (VAL), een interactief spraakherkenningssysteem via de telefoon. Dit systeem stond aan de wieg van de talloze keuzemenu-systemen die vandaag de dag nog steeds bestaan.
Jaren 2000
Tegen het jaar 2001 had spraakherkenningstechnologie een nauwkeurigheid van bijna 80% bereikt. Het grootste deel van het decennium waren er niet veel ontwikkelingen, totdat Google arriveerde met de lancering van Google Voice Search. Omdat het een app was, bracht dit spraakherkenning binnen het bereik van miljoenen mensen. Het was ook belangrijk omdat de verwerkingskracht kon worden uitbesteed aan datacenters. Bovendien verzamelde Google gegevens van miljarden zoekopdrachten, wat hielp om te voorspellen wat een persoon daadwerkelijk zegt. Destijds bevatte het Engelse Google Voice Search-systeem 230 miljard woorden uit zoekopdrachten van gebruikers.
Jaren 2010
In 2011 lanceerde Apple Siri, vergelijkbaar met Google Voice Search. In het eerste deel van dit decennium was er een explosie van andere spraakherkennings-apps. En met Amazon's Alexa en Google Home hebben we gezien dat consumenten steeds comfortabeler worden in het praten tegen machines.
Vandaag de dag strijden enkele van de grootste technologiebedrijven om de titel van meest nauwkeurige spraakherkenning. In 2016 behaalde IBM een foutpercentage van 6,9 procent. In 2017 passeerde Microsoft IBM met een claim van 5,9 procent. Kort daarna verbeterde IBM zijn percentage naar 5,5 procent. Het is echter Google dat het laagste percentage claimt met 4,9 procent.
De toekomst van spraakherkenning
De technologie om stemapplicaties te ondersteunen is nu zowel relatief goedkoop als krachtig. Met de vooruitgang in kunstmatige intelligentie en de toenemende hoeveelheden spraakdata die eenvoudig kunnen worden geanalyseerd, is het zeer goed mogelijk dat stem de volgende dominante interface wordt.
Bij Sonix danken we de vele bedrijven die ons zijn voorgegaan en die spraakherkenning hebben gebracht waar het nu is. Wij automatiseren de transcriptie-workflow en maken deze snel, eenvoudig en betaalbaar. Dat zouden we niet kunnen doen zonder het geweldige werk dat vóór ons is verricht.
Probeer Sonix gratis
Sonix transcribeert, tijdstempelt en organiseert je audio- en videobestanden, zodat je je media kunt doorzoeken, bewerken en delen.
Inclusief 30 minutes minuten gratis transcriptie