Uma curta história do
reconhecimento de voz
Houve mais progresso na tecnologia de reconhecimento de voz nos últimos 30 meses do que nos primeiros 30 anos.
O poder de processamento e a inteligência artificial estão em grande parte por trás dos avanços neste espaço. Com quantidades massivas de dados de fala combinadas com um processamento mais rápido, o reconhecimento de voz atingiu um ponto de inflexão onde suas capacidades estão praticamente no mesmo nível dos humanos.
O gráfico abaixo é do relatório Internet Trends 2017 de Mary Meeker (editado: não disponível mais no Slideshare). Ele traça a taxa de precisão de palavras do Google, que recentemente quebrou o limite de 95% para a precisão humana.
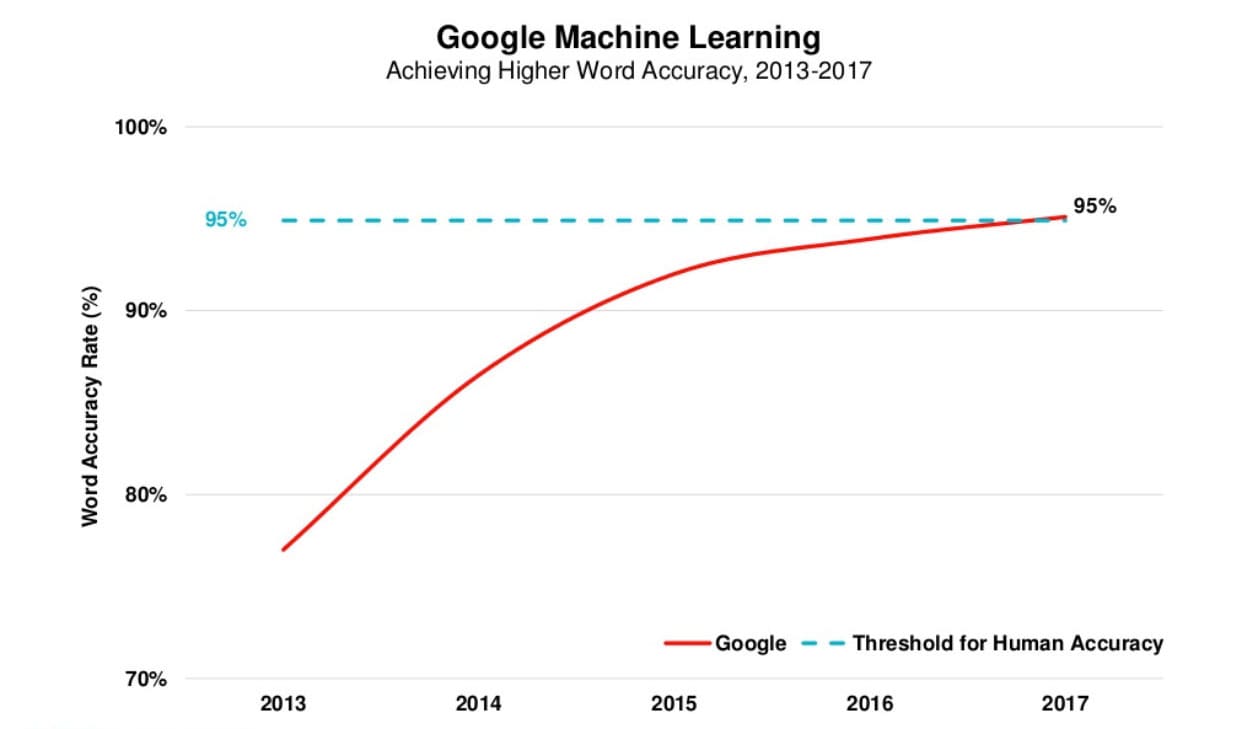
Embora tenha havido muitos avanços recentemente, o reconhecimento de voz remonta ao início da década de 1950. Abaixo estão alguns dos principais eventos que moldaram essa tecnologia nos últimos 70 anos.
Décadas de 1950 e 60
Os primeiros sistemas de reconhecimento de voz focavam em números, não em palavras. Em 1952, a Bell Laboratories projetou o sistema "Audrey", que conseguia reconhecer uma única voz falando dígitos em voz alta. Dez anos depois, a IBM apresentou o "Shoebox", que entendia e respondia a 16 palavras em inglês.
Em todo o mundo, outras nações desenvolveram hardware que conseguia reconhecer som e fala. E no final dos anos 60, a tecnologia já suportava palavras com quatro vogais e nove consoantes.
Anos 1970
O reconhecimento de voz deu vários passos significativos nesta década. Isso se deveu principalmente ao Departamento de Defesa dos EUA e à DARPA. O programa Speech Understanding Research (SUR) que eles executaram foi um dos maiores do gênero na história do reconhecimento de voz. O sistema de fala "Harpy" da Carnegie Mellon surgiu deste programa e era capaz de entender mais de 1.000 palavras, o que equivale aproximadamente ao vocabulário de uma criança de três anos.
Também foi significativo nos anos 70 a introdução pela Bell Laboratories de um sistema que conseguia interpretar múltiplas vozes.
Anos 1980
Os anos 80 viram o vocabulário do reconhecimento de voz passar de algumas centenas de palavras para vários milhares de palavras. Um dos avanços veio de um método estatístico conhecido como "Modelo Oculto de Markov (HMM)". Em vez de apenas usar palavras e procurar padrões sonoros, o HMM estimava a probabilidade de os sons desconhecidos serem, de fato, palavras.
Anos 1990
O reconhecimento de voz foi impulsionado nos anos 90, em grande parte, por causa do computador pessoal. Processadores mais rápidos tornaram possível que softwares como o Dragon Dictate se tornassem mais amplamente utilizados.
A BellSouth introduziu o portal de voz (VAL), que era um sistema de reconhecimento de voz interativo por discagem. Este sistema deu origem aos inúmeros sistemas de atendimento automático por telefone que ainda existem hoje.
Anos 2000
No ano de 2001, a tecnologia de reconhecimento de voz havia atingido quase 80% de precisão. Durante a maior parte da década, não houve muitos avanços até que o Google chegou com o lançamento do Google Voice Search. Por ser um aplicativo, isso colocou o reconhecimento de voz nas mãos de milhões de pessoas. Também foi significativo porque o poder de processamento podia ser transferido para seus data centers. Além disso, o Google estava coletando dados de bilhões de pesquisas, o que ajudava a prever o que uma pessoa estava realmente dizendo. Na época, o sistema de busca por voz em inglês do Google incluía 230 bilhões de palavras provenientes de pesquisas de usuários.
Anos 2010
Em 2011 a Apple lançou a Siri, que era semelhante ao Voice Search do Google. A primeira parte desta década viu uma explosão de outros aplicativos de reconhecimento de voz. E com a Alexa da Amazon e o Google Home, vimos os consumidores se tornarem cada vez mais confortáveis em falar com máquinas.
Hoje, algumas das maiores empresas de tecnologia estão competindo para ostentar o título de precisão de fala. Em 2016, a IBM alcançou uma taxa de erro de palavras de 6,9 por cento. Em 2017, a Microsoft superou a IBM com uma reivindicação de 5,9 por cento. Pouco depois, a IBM melhorou sua taxa para 5,5 por cento. No entanto, é o Google que reivindica a taxa mais baixa, de 4,9 por cento.
O futuro do reconhecimento de voz
A tecnologia para suportar aplicativos de voz agora é relativamente barata e poderosa ao mesmo tempo. Com os avanços na inteligência artificial e a quantidade crescente de dados de fala que podem ser facilmente minerados, é muito possível que a voz se torne a próxima interface dominante.
Na Sonix, agradecemos às muitas empresas que vieram antes de nós e que impulsionaram o reconhecimento de voz até onde ele está hoje. Automatizamos o fluxo de trabalho de transcrição e o tornamos rápido, fácil e acessível. Não poderíamos fazer isso sem o trabalho incrível que foi feito antes de nós.
Experimente o Sonix gratuitamente
O Sonix transcreve, gera carimbos de data/hora e organiza seus arquivos de áudio e vídeo para que você possa pesquisar, editar e compartilhar sua mídia.
Inclui 30 minutes minutos de transcrição gratuita