En kort historie om talegenkendelse
Der har været mere fremgang i talegenkendelsesteknologi i de sidste 30 måneder end i de første 30 år.
Regnekraft og kunstig intelligens står i høj grad bag fremskridtene på dette område. Med massive mængder taledata kombineret med hurtigere processering har talegenkendelse nået et vendepunkt, hvor dens evner er omtrent på højde med menneskers.
Grafen nedenfor er fra Mary Meekers Internet Trends-rapport for 2017 (red.: ikke længere tilgængelig på Slideshare). Den viser Googles ordnøjagtighed, som for nylig brød tærsklen på 95% for menneskelig nøjagtighed.
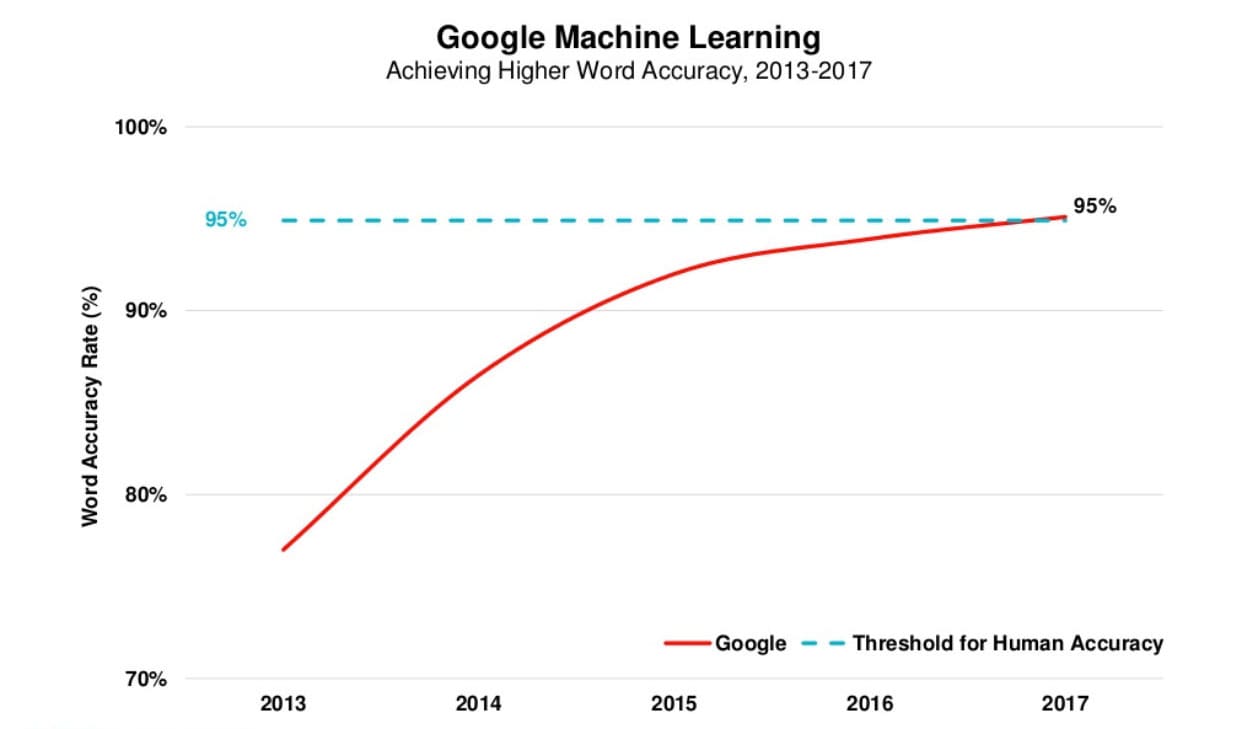
Selvom der har været mange store fremskridt på det seneste, går talegenkendelse helt tilbage til begyndelsen af 1950'erne. Nedenfor er nogle af de vigtigste begivenheder, der har formet denne teknologi over de sidste 70 år.
1950'erne og 60'erne
De første systemer til talegenkendelse fokuserede på tal, ikke ord. I 1952 designede Bell Laboratories "Audrey"-systemet, som kunne genkende en enkelt stemme, der læste cifre højt. Ti år senere introducerede IBM "Shoebox", som forstod og reagerede på 16 ord på engelsk.
Over hele kloden udviklede andre nationer hardware, der kunne genkende lyd og tale. Og ved slutningen af 60'erne kunne teknologien understøtte ord med fire vokaler og ni konsonanter.
1970'erne
Talegenkendelse gjorde flere betydningsfulde fremskridt i dette årti. Dette skyldtes primært det amerikanske forsvarsministerium og DARPA. Speech Understanding Research (SUR)-programmet, de kørte, var et af de største af sin art i talegenkendelsens historie. Carnegie Mellons "Harpy"-talesystem kom fra dette program og var i stand til at forstå over 1.000 ord, hvilket svarer nogenlunde til et barns ordforråd på tre år.
Ligeledes betydningsfuldt i 70'erne var Bell Laboratories' introduktion af et system, der kunne tolke flere stemmer.
1980'erne
I 80'erne gik talegenkendelsens ordforråd fra et par hundrede ord til flere tusinde ord. Et af gennembruddene kom fra en statistisk metode kendt som "Hidden Markov Model (HMM)". I stedet for blot at bruge ord og lede efter lydmønstre, estimerede HMM sandsynligheden for, at de ukendte lyde faktisk var ord.
1990'erne
Talegenkendelse blev drevet fremad i 90'erne i høj grad på grund af den personlige computer. Hurtigere processorer gjorde det muligt for software som Dragon Dictate at blive mere udbredt.
BellSouth introducerede stemmeportalen (VAL), som var et interaktivt talegenkendelsessystem via opkald. Dette system fødte de utallige telefonsvarersystemer, der stadig eksisterer i dag.
2000'erne
Inden år 2001 havde talegenkendelsesteknologien opnået tæt på 80% nøjagtighed. I det meste af årtiet skete der ikke mange fremskridt, før Google ankom med lanceringen af Google Voice Search. Fordi det var en app, lagde det talegenkendelse i hænderne på millioner af mennesker. Det var også betydningsfuldt, fordi processorkraften kunne udliciteres til deres datacentre. Ikke nok med det, Google indsamlede data fra milliarder af søgninger, hvilket kunne hjælpe med at forudsige, hvad en person rent faktisk siger. På det tidspunkt omfattede Googles engelske Voice Search-system 230 milliarder ord fra brugersøgninger.
2010'erne
I 2011 lancerede Apple Siri, som lignede Googles Voice Search. Den tidlige del af dette årti så en eksplosion af andre apps til talegenkendelse. Og med Amazons Alexa og Google Home har vi set forbrugerne blive mere og mere trygge ved at tale til maskiner.
I dag konkurrerer nogle af de største teknologivirksomheder om at føre an i titlen for talenøjagtighed. I 2016 opnåede IBM en ordfejlrate på 6,9 procent. I 2017 overhalede Microsoft IBM med en påstand om 5,9 procent. Kort efter forbedrede IBM deres rate til 5,5 procent. Det er dog Google, der hævder den laveste rate på 4,9 procent.
Fremtiden for talegenkendelse
Teknologien til at understøtte stemmeapplikationer er nu både relativt billig og kraftfuld. Med fremskridtene inden for kunstig intelligens og de stigende mængder taledata, der nemt kan udvindes, er det meget muligt, at stemmen bliver den næste dominerende grænseflade.
Hos Sonix kan vi takke de mange virksomheder før os, som har drevet talegenkendelse til det punkt, hvor det er i dag. Vi automatiserer arbejdsgangen for transskription og gør den hurtig, nem og overkommelig. Det kunne vi ikke gøre uden det fantastiske arbejde, der er blevet udført før os.
Prøv Sonix gratis
Sonix transskriberer, tidsstempler og organiserer dine lyd- og videofiler, så du kan søge i, redigere og dele dine medier.
Inkluderer 30 minutes minutters gratis transskription