Краткая история распознавания речи
За последние 30 месяцев в технологии распознавания речи было достигнуто больше прогресса, чем за первые 30 лет.
Вычислительная мощность и искусственный интеллект стоят за достижениями в этой области. Благодаря огромным объемам речевых данных в сочетании с более быстрой обработкой, распознавание речи достигло переломного момента, когда его возможности примерно сравнялись с человеческими.
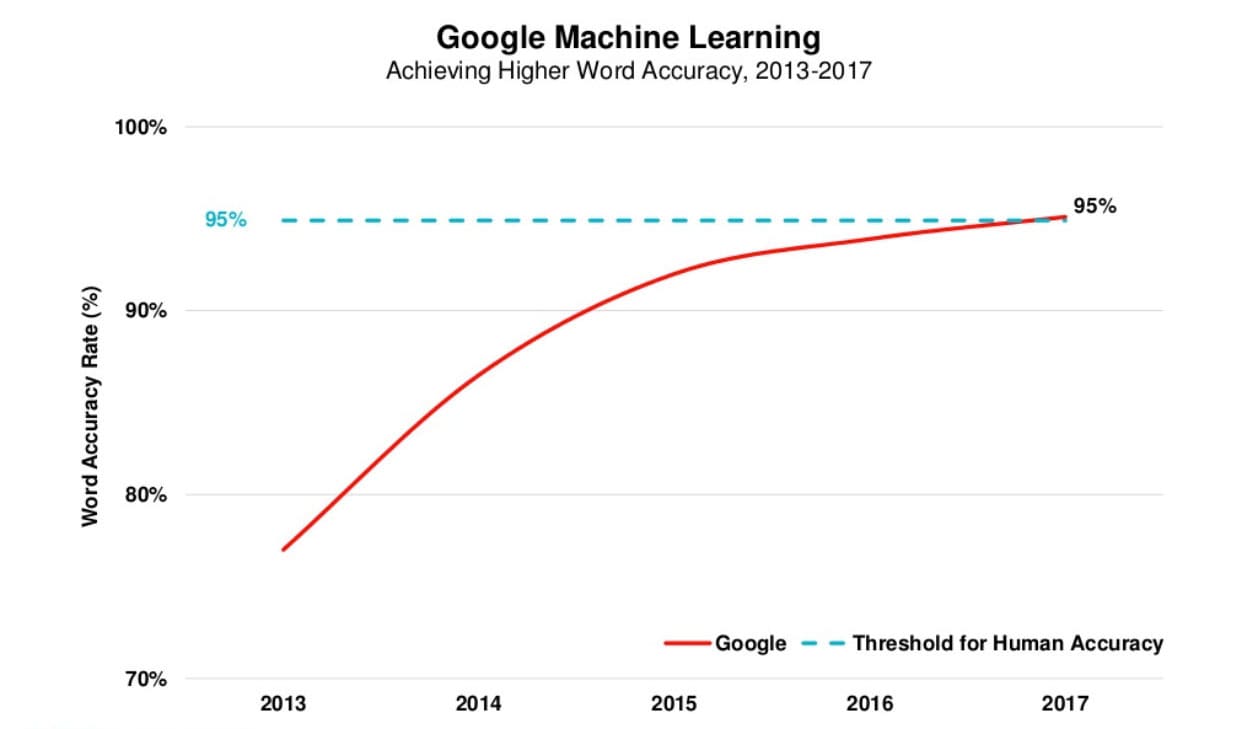
Приведенный ниже график взят из отчета Мэри Микер о тенденциях в интернете за 2017 год (прим.: больше недоступен на Slideshare). На нем отражен уровень точности распознавания слов Google, который недавно преодолел порог в 95% — уровень точности человека.
Хотя в последнее время был сделан огромный шаг вперед, история распознавания голоса восходит к началу 1950-х годов. Ниже приведены некоторые ключевые события, сформировавшие эту технологию за последние 70 лет.
1950-е и 60-е годы
Первые системы распознавания речи были ориентированы на цифры, а не на слова. В 1952 году Bell Laboratories разработала систему «Audrey», которая могла распознавать цифры, произносимые вслух одним голосом. Десять лет спустя IBM представила «Shoebox», которая понимала и реагировала на 16 слов на английском языке.
По всему миру и в других странах разрабатывалось оборудование, способное распознавать звук и речь. К концу 60-х годов технология уже поддерживала слова с четырьмя гласными и девятью согласными.
1970-е годы
В это десятилетие распознавание речи сделало несколько значимых шагов вперед. В основном это произошло благодаря Министерству обороны США и DARPA. Программа Speech Understanding Research (SUR), которую они проводили, была одной из крупнейших в своем роде в истории распознавания речи. Речевая система «Harpy» от Carnegie Mellon появилась в рамках этой программы и была способна понимать более 1000 слов, что примерно соответствует словарному запасу трехлетнего ребенка.
Также значимым событием 70-х годов стало внедрение в Bell Laboratories системы, способной интерпретировать несколько голосов.
1980-е годы
В 80-е годы словарный запас систем распознавания речи вырос с нескольких сотен до нескольких тысяч слов. Один из прорывов был связан со статистическим методом, известным как «Скрытая марковская модель (HMM)». Вместо того чтобы просто использовать слова и искать звуковые паттерны, HMM оценивала вероятность того, что неизвестные звуки на самом деле являются словами.
1990-е годы
Распознавание речи продвинулось вперед в 90-е годы во многом благодаря персональному компьютеру. Более быстрые процессоры позволили программному обеспечению, такому как Dragon Dictate, получить более широкое распространение.
BellSouth представила голосовой портал (VAL), который представлял собой интерактивную систему распознавания голоса с набором номера. Эта система дала жизнь множеству систем телефонного меню, которые существуют и сегодня.
2000-е годы
К 2001 году технология распознавания речи достигла точности почти 80%. На протяжении большей части десятилетия значительных достижений не было, пока не появился Google с запуском Google Voice Search. Поскольку это было приложение, оно передало распознавание речи в руки миллионов людей. Это было также важно, потому что вычислительная мощность могла быть перенесена в дата-центры. Более того, Google собирал данные миллиардов поисковых запросов, что помогало предсказывать, что на самом деле говорит человек. В то время система голосового поиска Google на английском языке включала 230 миллиардов слов из поисковых запросов пользователей.
2010-е годы
В 2011 году Apple запустила Siri, которая была похожа на Google Voice Search. В начале этого десятилетия произошел взрыв других приложений для распознавания голоса. А с появлением Amazon Alexa и Google Home мы увидели, что потребители все больше и больше привыкают разговаривать с машинами.
Сегодня некоторые из крупнейших технологических компаний соревнуются за звание лидера по точности речи. В 2016 году IBM достигла уровня ошибок в словах 6,9 процента. В 2017 году Microsoft обошла IBM с результатом 5,9 процента. Вскоре после этого IBM улучшила свой показатель до 5,5 процента. Однако именно Google заявляет о самом низком показателе — 4,9 процента.
Будущее распознавания речи
Технология для поддержки голосовых приложений сейчас стала одновременно относительно недорогой и мощной. С достижениями в области искусственного интеллекта и увеличением объема речевых данных, которые можно легко собирать, вполне возможно, что голос станет следующим доминирующим интерфейсом.
В Sonix мы благодарны многим компаниям, которые были до нас и продвинули распознавание речи до сегодняшнего уровня. Мы автоматизируем процесс транскрибации и делаем его быстрым, простым и доступным. Мы не смогли бы этого сделать без той огромной работы, которая была проделана ранее.
Попробуйте Sonix бесплатно
Sonix транскрибирует, расставляет временные метки и систематизирует ваши аудио- и видеофайлы, чтобы вы могли искать, редактировать и делиться своим контентом.
Включает 30 minutes минут бесплатной транскрипции