Une courte histoire de la
reconnaissance vocale
Il y a eu plus de progrès dans la technologie de reconnaissance vocale au cours des 30 derniers mois qu'au cours des 30 premières années.
La puissance de calcul et l'intelligence artificielle sont largement à l'origine des avancées dans ce domaine. Grâce à des quantités massives de données vocales combinées à un traitement plus rapide, la reconnaissance vocale a atteint un point d'inflexion où ses capacités sont pratiquement à la hauteur de celles des humains.
Le graphique ci-dessous est tiré du rapport Internet Trends 2017 de Mary Meeker (note : plus disponible sur Slideshare). Il trace le taux de précision des mots de Google qui a récemment franchi le seuil de 95% de la précision humaine.
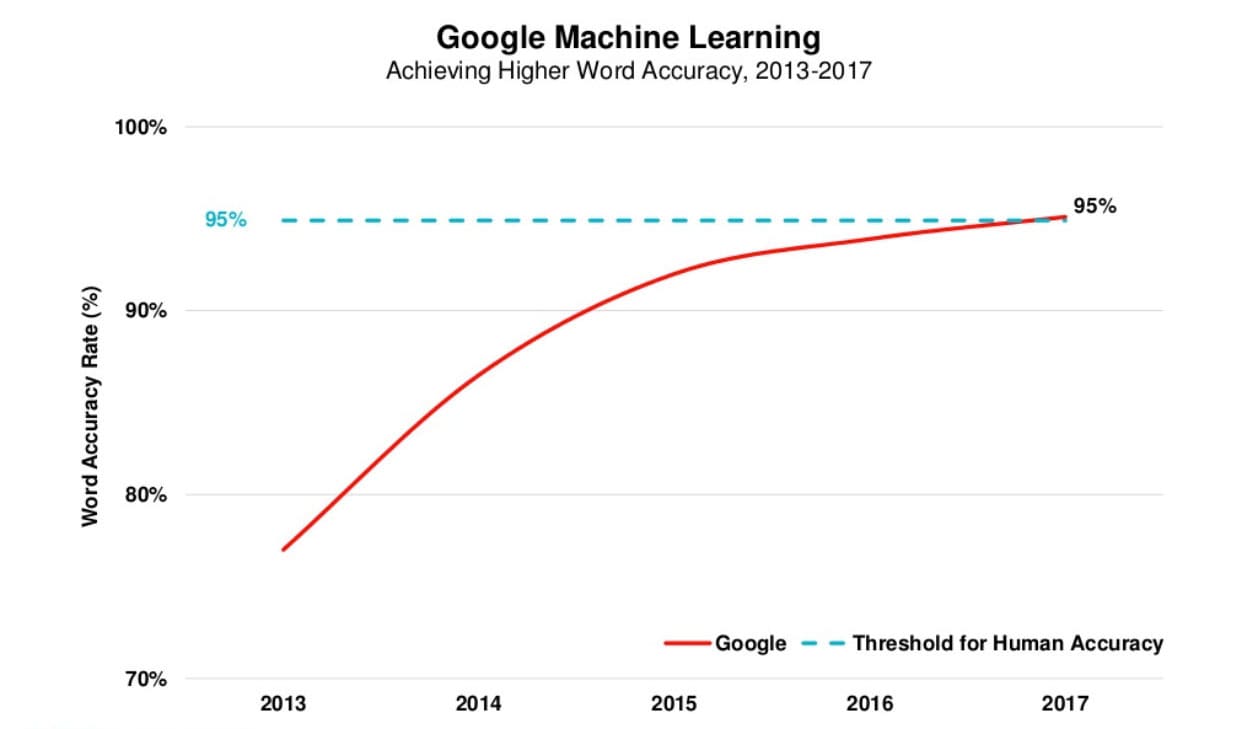
Bien qu'il y ait eu énormément de progrès récemment, la reconnaissance vocale remonte au début des années 1950. Vous trouverez ci-dessous quelques-uns des événements clés qui ont façonné cette technologie au cours des 70 dernières années.
Années 1950 et 60
Les premiers systèmes de reconnaissance vocale se concentraient sur les chiffres, pas sur les mots. En 1952, Bell Laboratories a conçu le système « Audrey » qui pouvait reconnaître une seule voix prononçant des chiffres à haute voix. Dix ans plus tard, IBM a présenté « Shoebox » qui comprenait et répondait à 16 mots en anglais.
À travers le monde, d'autres nations ont développé du matériel capable de reconnaître le son et la parole. Et à la fin des années 60, la technologie pouvait prendre en charge des mots avec quatre voyelles et neuf consonnes.
Années 1970
La reconnaissance vocale a fait plusieurs progrès significatifs au cours de cette décennie. Cela est dû principalement au département de la Défense des États-Unis et à la DARPA. Le programme Speech Understanding Research (SUR) qu'ils ont mené était l'un des plus importants de ce type dans l'histoire de la reconnaissance vocale. Le système vocal « Harpy » de Carnegie Mellon est issu de ce programme et était capable de comprendre plus de 1 000 mots, ce qui correspond environ au vocabulaire d'un enfant de trois ans.
Également important dans les années 70, l'introduction par Bell Laboratories d'un système capable d'interpréter plusieurs voix.
Années 1980
Les années 80 ont vu le vocabulaire de la reconnaissance vocale passer de quelques centaines de mots à plusieurs milliers de mots. L'une des percées est venue d'une méthode statistique connue sous le nom de « Hidden Markov Model (HMM) ». Au lieu de simplement utiliser des mots et de chercher des modèles sonores, le HMM estimait la probabilité que les sons inconnus soient réellement des mots.
Années 1990
La reconnaissance vocale a été propulsée vers l'avant dans les années 90 en grande partie grâce à l'ordinateur personnel. Des processeurs plus rapides ont permis à des logiciels comme Dragon Dictate d'être plus largement utilisés.
BellSouth a introduit le portail vocal (VAL), qui était un système de reconnaissance vocale interactif par téléphone. Ce système a donné naissance à la myriade de serveurs vocaux interactifs qui existent encore aujourd'hui.
Années 2000
En 2001, la technologie de reconnaissance vocale avait atteint une précision de près de 80%. Pendant la majeure partie de la décennie, il n'y a pas eu beaucoup d'avancées jusqu'à ce que Google arrive avec le lancement de Google Voice Search. Comme il s'agissait d'une application, cela a mis la reconnaissance vocale entre les mains de millions de personnes. C'était également important car la puissance de traitement pouvait être déportée vers ses centres de données. De plus, Google collectait des données à partir de milliards de recherches, ce qui pouvait l'aider à prédire ce qu'une personne disait réellement. À l'époque, le système de recherche vocale en anglais de Google comprenait 230 milliards de mots issus des recherches des utilisateurs.
Années 2010
En 2011, Apple a lancé Siri, qui était similaire à Google Voice Search. Le début de cette décennie a vu une explosion d'autres applications de reconnaissance vocale. Et avec Alexa d'Amazon et Google Home, nous avons vu les consommateurs devenir de plus en plus à l'aise pour parler aux machines.
Aujourd'hui, certaines des plus grandes entreprises technologiques se battent pour le titre de la précision vocale. En 2016, IBM a atteint un taux d'erreur de mots de 6,9 pour cent. En 2017, Microsoft a détrôné IBM avec une affirmation de 5,9 pour cent. Peu après, IBM a amélioré son taux à 5,5 pour cent. Cependant, c'est Google qui revendique le taux le plus bas à 4,9 pour cent.
Le futur de la reconnaissance vocale
La technologie permettant de prendre en charge les applications vocales est désormais à la fois relativement peu coûteuse et puissante. Avec les progrès de l'intelligence artificielle et les quantités croissantes de données vocales pouvant être facilement exploitées, il est très possible que la voix devienne la prochaine interface dominante.
Chez Sonix, nous pouvons remercier les nombreuses entreprises qui nous ont précédés et qui ont propulsé la reconnaissance vocale là où elle en est aujourd'hui. Nous automatisons le flux de travail de transcription et le rendons rapide, facile et abordable. Nous ne pourrions pas faire cela sans le travail incroyable accompli avant nous.
Essayez Sonix gratuitement
Sonix transcrit, ajoute des horodatages et organise vos fichiers audio et vidéo afin que vous puissiez rechercher, éditer et partager vos médias.
Comprend 30 minutes de transcription gratuite